Plank partnered with the ARC Prize team to build and open-source a LangGraph starter agent - a stateful, multi-agent template that can solve the first game (LS20) from their latest reasoning benchmark - ARC-AGI-3. Instead of hardcoding the rules, this agent template combines memory, vision, planning, and spatial reasoning inside a multi-agent graph, showing how systems can learn and adapt to new environments. This template is designed as a starting codebase for anyone interested in building an agent to solve this new benchmark.
Why ARC-AGI-3 Matters
Traditionally, to measure intelligence, static benchmarks have been the yardstick, but they do not have the bandwidth required to measure the full spectrum of intelligence. ARC-AGI-1 and ARC-AGI-2 are examples of static benchmarks.
Most benchmarks in AI today are static, i.e. they use fixed datasets where models are scored by comparing their outputs against pre-defined answers. ARC-AGI-1 and ARC-AGI-2 are examples of this approach. While they’re valuable, they only test narrow capabilities.
ARC-AGI-3 is the first large-scale Interactive Reasoning Benchmarks (IRBs) and represents a new paradigm. Instead of one-shot tasks, it places agents in dynamic environments where they must demonstrate broader capabilities:
- Exploration
- Percept -> Plan → Action
- Memory
- Goal Acquisition
- Alignment
ARC-AGI-3 will feature ~100 unique environments (six are already public) where agents must perceive, decide, and act without prior instructions. Success depends not on memorization, but on how quickly an agent can acquire new skills and generalize across unseen tasks.
LS20: The First Game
The first ARC-AGI-3 game, LS20, is deceptively simple:
- A locked door only opens when the player’s key matches its shape.
- Moving across a “rotator” cycles the held key through different shapes.
- Every move costs one health point.

To play LS-20 effectively, we created an agent using LangGraph with the following skills:
- Memory to track observations about the game environment between attempts.
- Vision to identify various objects and structures present in the environment.
- Planning to avoid wasting health on low-value movements.
- Spatial reasoning in order to navigate through the environment.
It’s important to note that while hardcoding these rules would have solved LS20, it would not teach the agent anything for the 99+ other games. The objective was to build agents that bootstrap these skills themselves, i.e. can learn how to learn.
To help the community tackle this, we built a [starter agent template] on top of LangGraph, LangChain’s framework for stateful multi-agent systems, which we hope accelerates experimentation on building agents to solve ARC-AGI-3.
Why We Used LangGraph
We chose LangGraph because it enables stateful, multi-agent workflows. Unlike linear pipelines, LangGraph enables graph-based workflows where agents can collaborate, make decisions dynamically, and maintain state over long-running executions.
This flexibility is essential for ARC-AGI-3, where agents must evolve strategies across very different environments. Graph-based systems can capture the adaptability required that a static workflow cannot.
Here’s a simple example:
- A researcher agent can search the web or query SQL databases.
- A chart generator agent can run Python to visualize results.
A router coordinates them—either via deterministic rules or by acting as an agent itself.
.png)
This graph-based approach balances control (fixed transitions where appropriate) and agency (agent reasoning where paths can’t be predefined). Because LangGraph graphs are just code, supervisory agents can even modify the workflow at runtime.
That ability to rewire itself is critical for building recursively self-improving systems—the kind of systems that can tackle ARC-AGI-3. It’s the main reason we chose LangGraph as our foundation.
Our approach: bootstrapping LS20
We sprinted over a weekend to prototype an LS20-capable agent. Rather than chasing a perfect zero-shot solution, we followed an inside-out bootstrapping strategy:
- Start with hardcoded rules - use them as scaffolding.
- Iteratively remove the scaffolding - replace brittle logic with self-learned competence.
- Layer in memory, perception, planning, and reasoning - each component should generalize beyond LS20.
Memory
The obvious first step towards solving ARC-AGI-3 is to give the agent a way of reflecting on how its actions influence the game world (short term memory), and persisting those observations across executions (long term memory).
There are plenty of off-the-shelf LangGraph modules to choose from for long term memory, but we used SQLite to avoid the need to spin up a dedicated database process. For short term memory, we drew inspiration from Claude Code’s famous think tool:
# agent.py
import sqlite3
from langgraph.graph import StateGraph
from langgraph.store.sqlite import SqliteStore
from ...agent import Agent
from .schema import AgentState
class LangGraph(Agent):
def _build_workflow(self) -> None:
workflow = StateGraph(
AgentState,
input_schema=AgentState,
output_schema=AgentState,
)
# ...
return workflow.compile(
store=SqliteStore(
sqlite3.connect(
"memory.db",
check_same_thread=False,
isolation_level=None, # autocommit mode
),
),
)
# tools.py
import logging
import uuid
from langchain_core.tools import tool
from langgraph.config import get_store
log = logging.getLogger(__name__)
@tool
def think(thought: str) -> str:
"""
Think about your next action or what is happening in the environment.
This will not add an observation to your journal, so it is good for short-term thinking or reflection in the moment.
"""
log.info(f"🤔 {thought}")
return f"Thought: {thought}"
@tool
def delete_observation(id: str) -> str:
"""Delete an observation from your journal. Useful if you think it no longer applies."""
store = get_store()
store.delete(("observations"), id)
return f"Observation deleted with ID: {id}"
@tool
def observe(observation: str) -> str:
"""
Stores an observation about the game in your journal.
These observations are long-lived and will persist between game sessions.
Example: After confirming how ACTION1 works, it would be a good idea to store an observation about it for future reference.
"""
store = get_store()
id = uuid.uuid4()
log.info(f"👀 {observation}")
store.put(
("observations"),
id,
observation,
)
return f"Observation stored with ID: {id}"
all_tools = [think, delete_observation, observe]
We treat long-term memory as a set of observations and load them into the agent’s system prompt at each step, so the LLM can use them while solving the game.
Vision
We had hoped that memory alone would prove sufficient to make progress, but at this point the learning rate of the agent was painfully slow. Sometimes it’s possible to overcome this problem by running a large swarm of agents to parallelize the learning process, but in this case the agent learned so slowly that it didn’t seem like a useful experiment to run. It was clear that the agent needed some extra abilities to make meaningful progress on solving LS20.
The games of ARC-AGI-3 run on Arc Prize servers, and you interact with them over a RESTful API. The game frame is represented as a multi-dimensional JSON array, where each element’s position inside the array represents coordinates and the numeric value of each element represents a color:
[
[4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, ...],
[4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, ...],
[4, 4, 3, 4, 3, 4, 3, 4, 3, 4, 3, 4, 3, 4, 3, 4, 3, ...],
[4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, ...],
[4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, ...],
[4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, ...],
[4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, ...],
[4, 4, 4, 4, 4, 4, 4, 4, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...],
[4, 4, 4, 4, 4, 4, 4, 4, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...],
[4, 4, 4, 4, 4, 4, 4, 4, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...],
...
]Note: In reality, the frame data comes back as a 3D array - LS20 produces only one frame per action, but future games may generate multiple frames in between actions to represent things like animations!
By saving a copy of the frame data to disk and comparing each element in the JSON array with the real rendered game, it is possible to determine what color each value represents. From there it is simple to loop over the frame data and render the frame using the Pillow module in Python. We adapted the color palette to increase the contrast ratio between different objects, to make the segmentation between objects more obvious to the LLM.
Here’s an example of a frame rendered by the helper function:

Including this image in the agent’s context window did not help much on its own, but by including the previous frame as well, we started to see more interesting agent output. The model was capable of recognizing that the player object moved when it interacted with the game, although it wasn’t yet quite smart enough to figure out that the object being moved represented the player.
Inspired by Browser Use’s vision implementation, the next iteration on this experiment added highlights around important elements inside the frame. This gave the agent the vocabulary necessary to describe its observations about changes in the game state more directly:

Planning via prompt hints
At this point the agent was capable of learning what each action in the game achieved (namely, movement of the player object!) but still struggled to determine the overall goal of the game environment. It would simply meander around the room until it ran out of lives and had to reset.
It’s possible that with enough runs the agent would eventually figure out how the rotator interacts with the player and the held key, but in the interest of time we opted to take a shortcut and gave the agent more context about the game rules inside its system prompt:
def build_system_prompt(
observations: list[Observation],
thoughts: list[str],
) -> str:
# ...
return dedent(
f"""
...
Hints:
1. Reach the door while holding the correct key to win the game
2. The key you are holding is visible in the bottom-left corner of the frame
3. Green elements in the environment are walls - you cannot move through them
4. The key you are holding can be changed by colliding with a rotator
...
"""
)
We were now much closer to solving the first level of LS20. The agent’s internal thoughts showed that it was capable of making a plan to use the rotator to obtain the correct key, but it would often fail to find a path to the rotator and would also fail to compare the shape of the key against that of the door. We needed to start thinking about how to add spatial reasoning to the agent’s set of capabilities.
Spatial reasoning
There are two kinds of spatial reasoning necessary to solve LS20:
- First, the agent needs to be capable of recognizing when the key held by the player matches or differs from the key accepted by the door.
- Second, the agent needs to be capable of figuring out efficient paths for the player to take to reach interesting objects in the game environment. Each movement consumes one point of health, which means inefficient movement can result in a loss.
To solve the key-matching problem, we added a new node to our LangGraph graph that is solely responsible for comparing the player’s key with the door. The output of that comparison is stored in the agent’s state, ready to be consumed by the node that decides which action to take in the game environment.
Pathfinding is trickier. Our initial approach was to implement an A* pathfinding tool which the agent could use to determine the shortest path to a destination after it decided on a destination point. This worked reasonably well, but it isn’t a particularly generic solution.
Consider the second game of the batch: FT09. This is a totally different game environment with no player movement at all; instead, you click on tiles with the mouse in order to create a pattern which matches the target pattern.

If we could avoid hardcoding a pathfinding step into our agent loop, it would be the first concrete step towards generalizing the agent for the various ARC-AGI-3 games.
The human eye detects motion through pathways which activate when light patterns shift across the retina. Those basic signals are interpreted into more complicated perceptual constructs like object tracking and trajectory prediction through subsequent layers of neural processing.
This vision mechanism can be transferred over to the agent fairly simply:
- We swapped the hardcoded pathfinding step with a more general “delta tracking” step. A multimodal LLM receives both the current frame and the previous frame of the game, and is responsible for explaining what has changed.
- The pre-existing system we built for the LLM to store long-term observations about the game world can then be used by the LLM as it begins to understand how its actions impact the game frame, and how the game frame represents the state of the game’s environment.
Implementing the general-purpose delta tracking step was sufficient on its own to remove the need for a dedicated pathfinding step, especially given that for now, we’re still giving the model lots of hints about the game rules in its system prompt. The next step from this point would be to expand the observation system so that it has more power to influence future agent executions. One idea would be to give the observation system the ability to generate its own prompts, and insert them into the graph. Over time the agent could refine these additional workflow stages in much the same way that evolution has refined the human vision system.
Combining these building blocks together yields an agent that can successfully solve the first level of LS20, using an optimal number of moves:
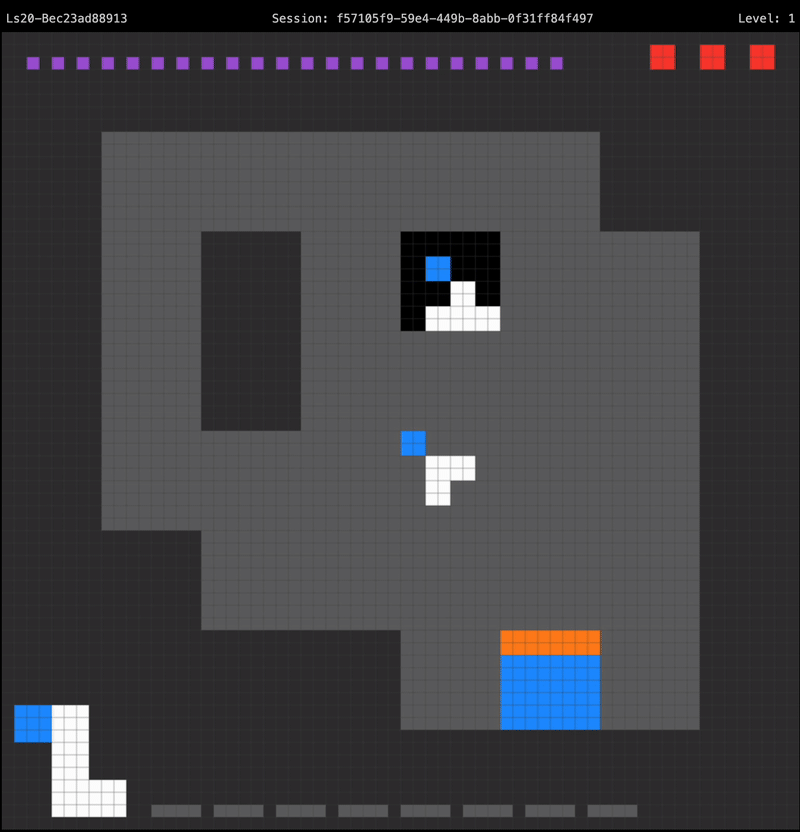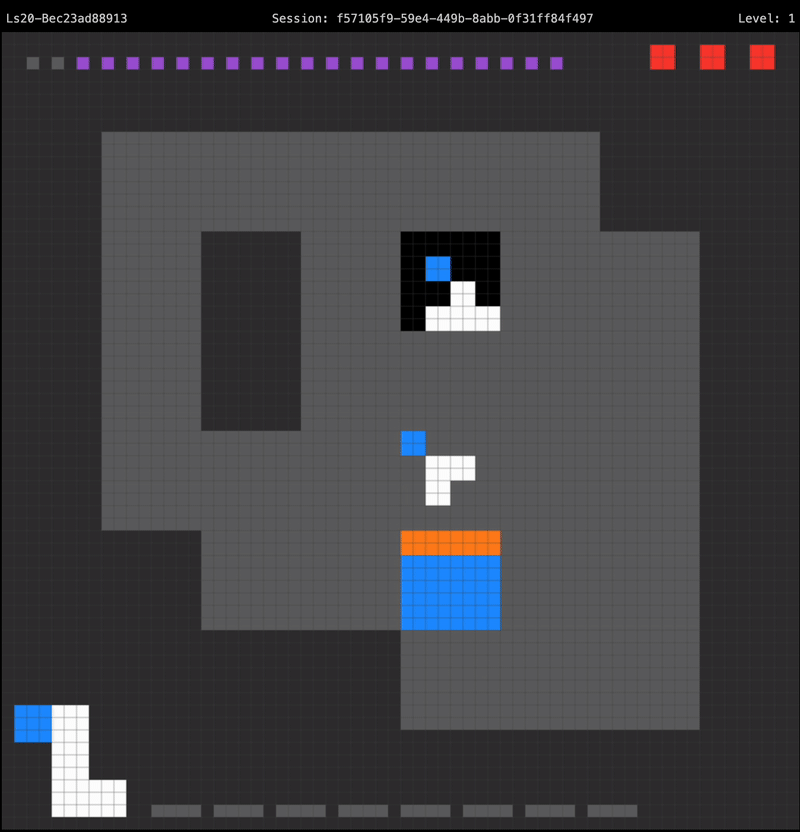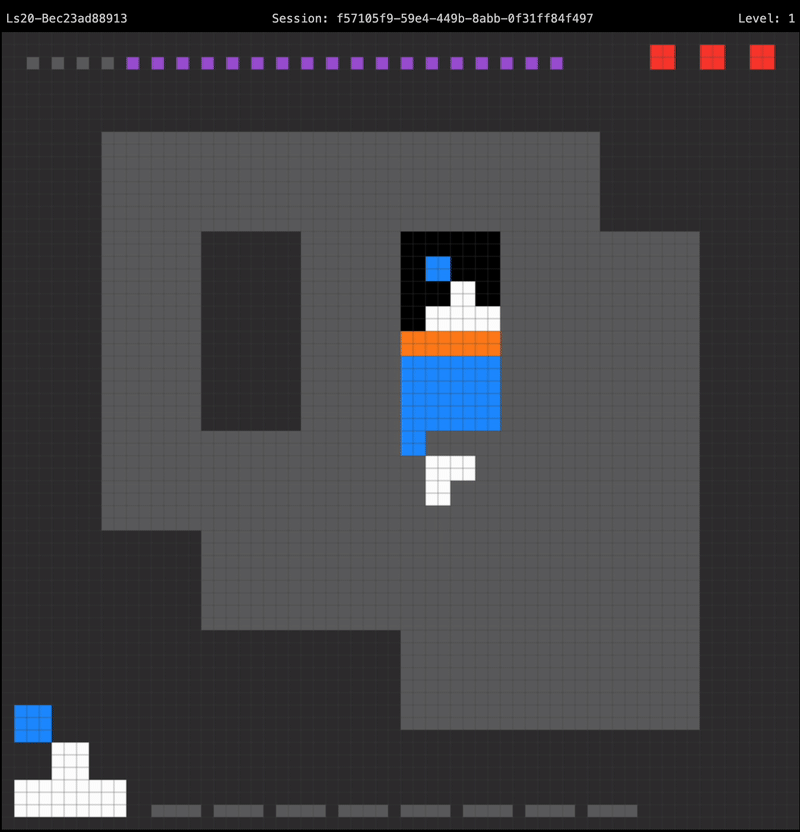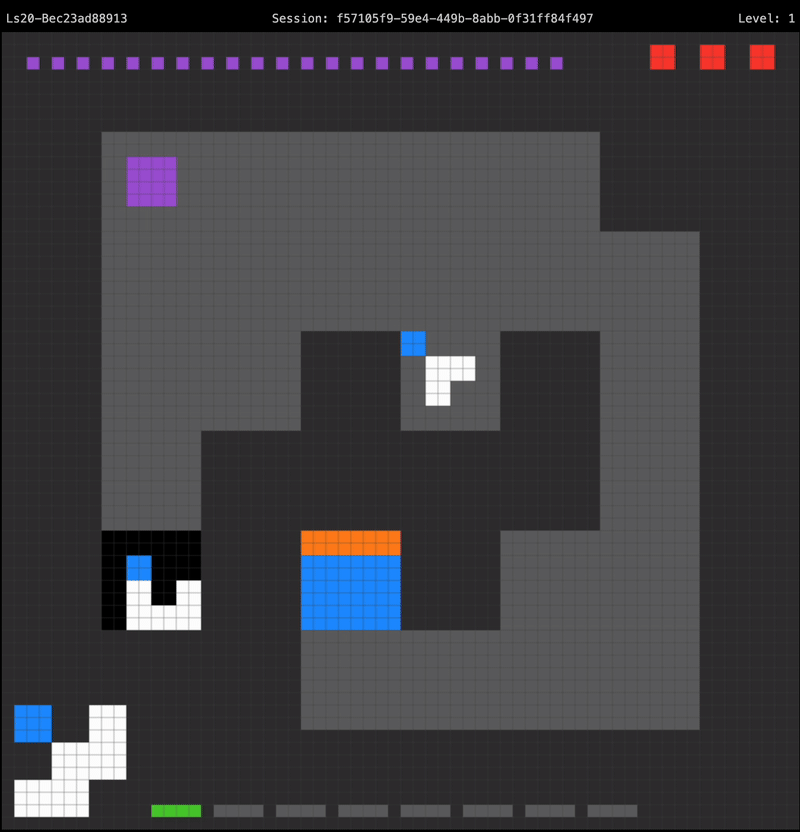
The agent recognizes it is holding the wrong key for the door upon starting the level, so it paths directly towards the rotator to swap out its held key. The first level only requires the player to hit the rotator a single time to obtain the correct key, so after reaching the rotator the agent paths straight to the door in order to proceed to the next level.
This is all done without needing a dedicated pathfinding step. Spatial reasoning, in combination with some hints in the prompt about the game environment is enough to get to this point.
The next level introduces more advanced concepts which require the agent to think about and execute on a long-term strategy. The player must use the rotator multiple times in order to obtain the correct key, but continuously using the rotator will consume all of the player’s health and reset them to the beginning of the level:

To solve this level, the player must strategically use the purple item in the top-left corner to replenish their health. Using the “replenisher” too soon will waste some of its healing abilityleaving the player with too little health to make it to the door, and moving towards it too late will mean the player has insufficient health to make it to the replenisher before dying.
The current LangGraph agent isn’t yet capable of solving the added challenge by itself, but this template can be extended to drive deeper progress in LS20.
Come solve AGI!
We hope that this has inspired you to try hacking on ARC-AGI-3, and given you some ideas to experiment with. The challenge of building systems that can learn and adapt their own problem-solving approaches is one of the most exciting frontiers in AI development, with applications that reach far beyond playing video games.
Our agent is open source, and we’d love to receive contributions if you can make it better!


